
This 1.5 release is unlike any of the previous ones. It brings many new features that can improve quality and the general audio experience. That is achieved through machine learning. Although Opus has included machine learning — and even deep learning — before (e.g. for speech/music detection), this is the first time it has used deep learning techniques to process or generate the signals themselves.
Instead of designing a new ML-based codec from scratch, we prefer to improve Opus in a fully-compatible way. That is an important design goal for ML in Opus. Not only does that ensure Opus keeps working on older/slower devices, but it also provides an easy upgrade path. Deploying a new codec can be a long, painful process. Compatibility means that older and newer versions of Opus can coexist, while still providing the benefits of the new version when available.
Deep learning also often gets associated with powerful GPUs, but in Opus, we have optimized everything such that it easily runs on most CPUs, including phones. We have been careful to avoid huge models (unlike LLMs with their hundreds of billions of parameters!). In the end, most users should not notice the extra cost, but people using older (5+ years) phones or microcontrollers might. For that reason, all new ML-based features are disabled by default in Opus 1.5. They require both a compile-time switch (for size reasons) and then a run-time switch (for CPU reasons).
The following sections describe the new features enabled by ML.
Packet loss is one of the main annoyances one can encounter during a call. It does not matter how good the codec is if the packets do not get through. That's why most codecs have packet loss concealment (PLC) that can fill in for missing packets with plausible audio that just extrapolates what was being said and avoids leaving a hole in the audio (a common thing to hear with Bluetooth headsets). PLC is a place where ML can help a lot. Instead of using carefully hand-tuned concealment heuristics, we can just let a Deep Neural Network (DNN) do it. The technical details are in our Interspeech 2022 paper, for which we got the second place in the Audio Deep Packet Loss Concealment Challenge.
When building Opus, using --enable-deep-plc will compile in the deep PLC code at a cost of about 1 MB in binary size. To actually enable it at run time, you will need to set the decoder complexity to 5 or more. Previously, only the encoder had a complexity knob, but the decoder is now getting one too. It can be set with the -dec_complexity option to opus_demo, or OPUS_SET_COMPLEXITY() in the API (like for the encoder). The extra complexity from running PLC at a high loss rate is about 1% of a laptop CPU core. Because deep PLC only affects the decoder, turning it on does not have any compatibility implications.
PLC is great for filling up occasional missing packets, but unfortunately packets often go missing in bursts. When that happens, entire phonemes or words are lost. Of course, new generative models could easily be used to seamlessly fill any gap with very plausible words, but we believe it is good to have the listener hear the same words that were spoken. The way to achieve that is through redundancy. Opus already includes a low-bitrate redundancy (LBRR) mechanism to transmit every speech frame twice, but only twice. While this helps reduce the impact of loss, there's only so much it can do for long bursts.
That is where ML can help. We were certainly not the first to think about using ML to make a very low bitrate speech codec. However (we think) we are the first to design one that is optimized solely for transmitting redundancy. A regular codec needs to have short packets (typically 20 ms) to keep the latency low and it has to limit its use of prediction specifically to avoid making the packet loss problem even worse. For redundancy, we don't have these problems. Each packet will contain a large (up to 1 second) chunk of redundant audio that will be transmitted all at once. Taking advantage of that, the Opus Deep REDundancy (DRED) uses a rate-distortion-optimized variational autoencoder (RDO-VAE) to efficiently compress acoustic parameters in such a way that it can transmit one second of redundancy with about 12-32 kb/s overhead. Every 20-ms packet is effectively transmitted 50 times at a cost similar to the existing LBRR. See this demo for a high-level overview of the science behind DRED, or read the ICASSP 2023 paper for all the details and math behind it.
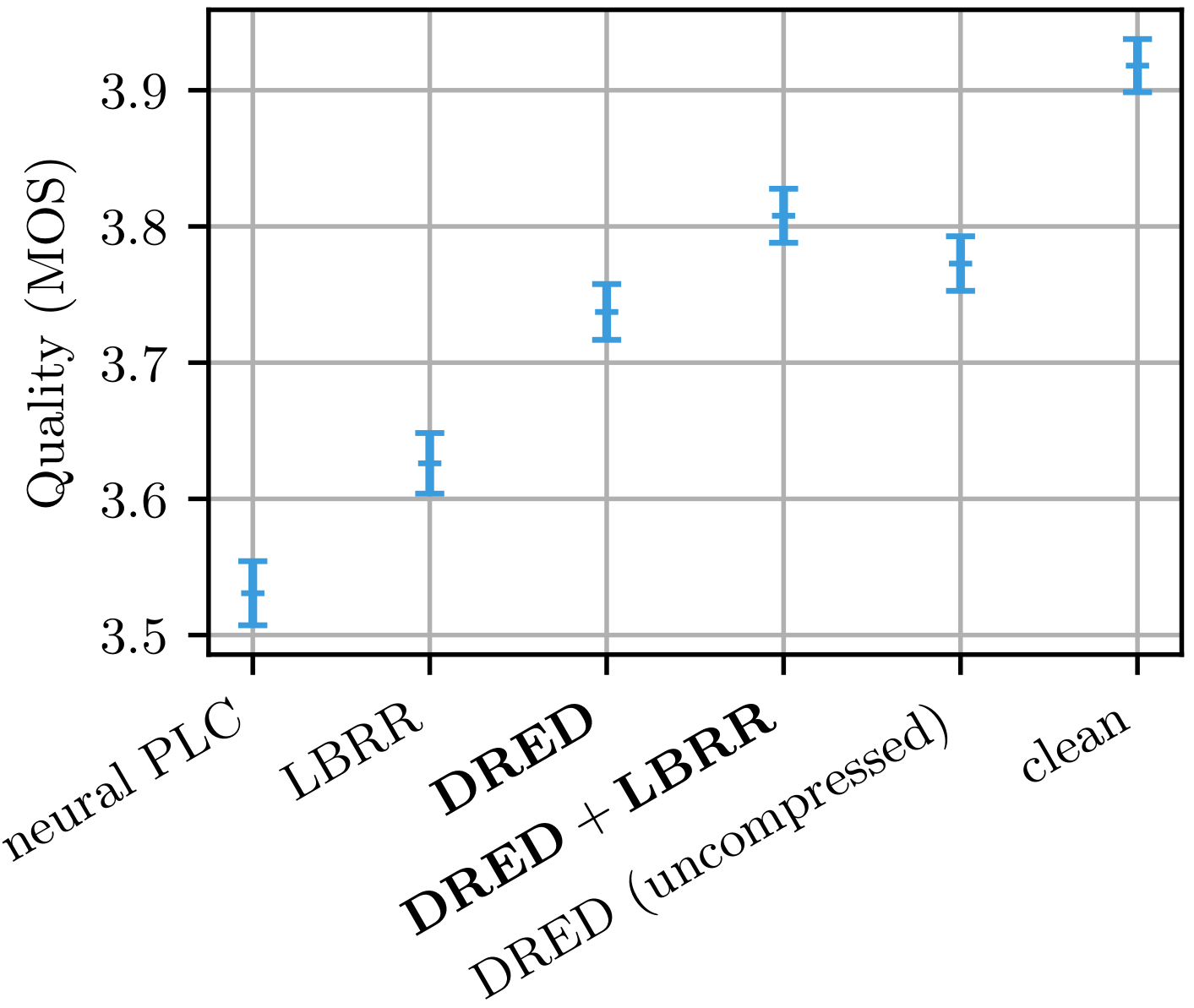
Use the --enable-dred configure option (which automatically turns on --enable-deep-plc) to enable DRED. Doing so increases the binary size by about 2 MB, with a run-time cost around 1% like for deep PLC. Beware that DRED is not yet standardized and the version included in Opus 1.5 will not be compatible with the final version. That being said, it is still safe to experiment with it in applications since the bitstream carries an experiment version number and any version incompatibility will be detected and simply cause the DRED payload to be ignored (no erroneous decoding or loud noises).
The very low complexity of deep PLC and DRED is made possible by new neural vocoder technology we created specifically for this project. The original papers linked above used a highly-optimized version of the original LPCNet vocoder, but even that was not quite fast enough. So we came up with a new framewise autoregressive generative adversarial network (FARGAN) vocoder that uses pitch prediction to achieve a complexity of 600 MFLOPS: 1/5 of LPCNet. That allows it to run with less than 1% of a CPU core on laptops or even recent phones. We don't yet have a paper or writeup on FARGAN, but we are working on fixing that.
Given enough bits, most speech codecs — including Opus — are able to reach a quality level close to transparency. Unfortunately, the real world sometimes doesn't give us "enough bits". Suddenly, the coding artifacts can become audible, or even annoying. The classical approach to mitigate this problem is to apply simple, handcrafted postfilters that reshape the coding noise to make it less noticeable. While those postfilters usually provide a noticeable improvement, their effectiveness is limited. They can't work wonders.
The rise of ML and DNNs has produced a number of new and much more powerful enhancement methods, but these are typically large, high in complexity, and cause additional decoder delay. Instead, we went for a different approach: start with the tried-and-true postfilter idea and sprinkle just enough DNN magic on top of it. Opus 1.5 includes two enhancement methods: the Linear Adaptive Coding Enhancer (LACE) and a Non-Linear variation (NoLACE). From the signal point of view, LACE is very similar to a classical postfilter. The difference comes from a DNN that optimizes the postfilter coefficients on-the-fly based on all the data available to the decoder. The audio itself never goes through the DNN. The result is a small and very-low-complexity model (by DNN standards) that can run even on older phones. An explanation of the internals of LACE is given in this short video presentation and more technical details can be found in the corresponding WASPAA 2023 paper. NoLACE is an extension of LACE that requires more computation but is also much more powerful due to extra non-linear signal processing. It still runs without significant overhead on recent laptop and smartphone CPUs. Technical details about NoLACE are given in the corresponding ICASSP 2024 paper.
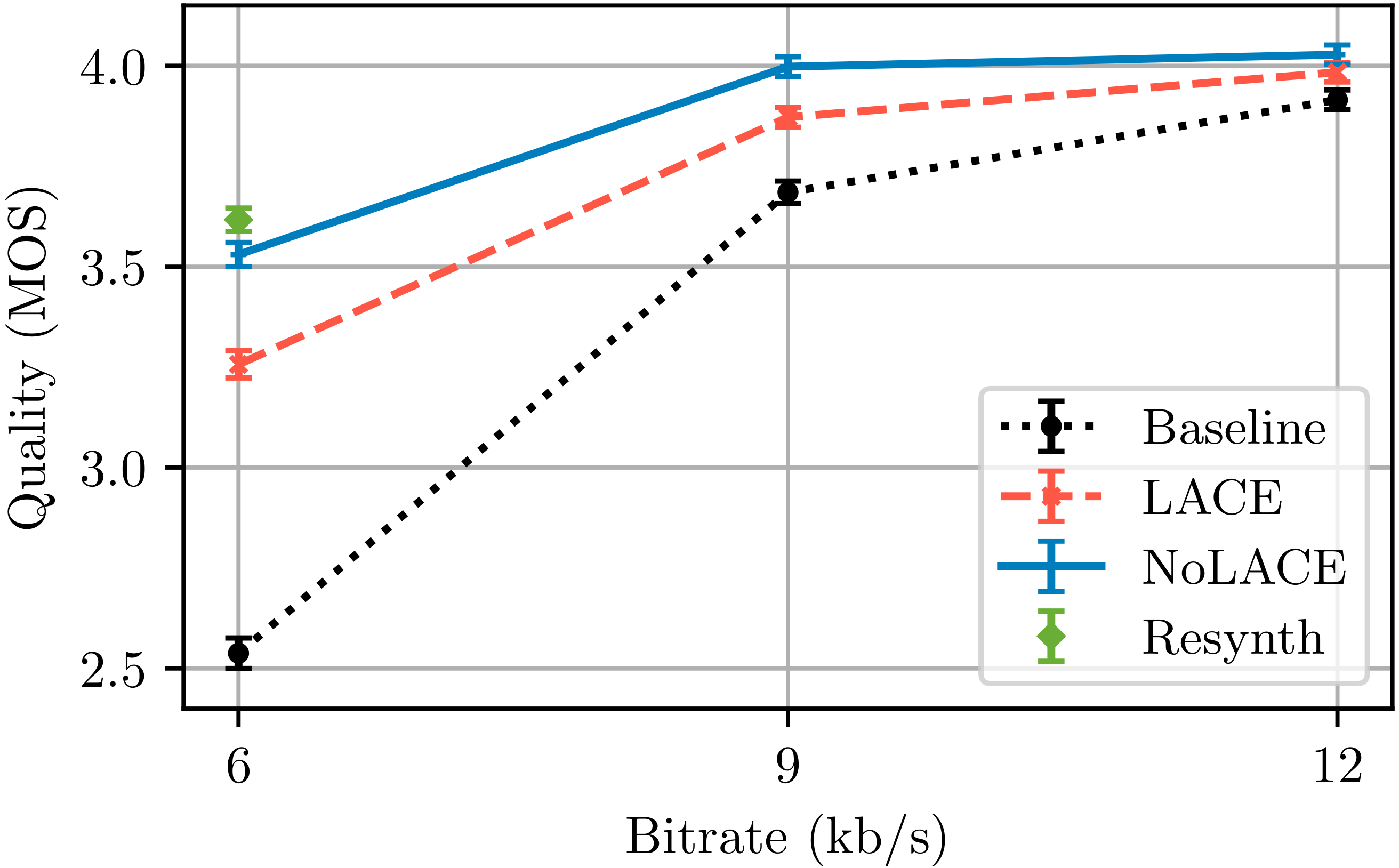
To try LACE and NoLACE, just add the --enable-osce configure flag when building Opus. Then, to enable LACE at run-time, set the decoder complexity to 6. Set it to 7 or higher to enable NoLACE instead of LACE. Building with --enable-osce increases the binary size by about 1.6 MB, roughly 0.5 MB for LACE and 1.1 MB for NoLACE. The LACE model has a complexity of 100 MFLOPS which leads to a run-time cost of ~0.15% CPU usage. The NoLACE model has a complexity of 400 MFLOPS which corresponds to a run-time cost of ~0.75% CPU usage. LACE and NoLACE are currently only applied when the frame size is 20 ms (the default) and the bandwidth is at least wideband. Although LACE and NoLACE have not yet been standardized, turning them on does not have compatibility implications since the enhancements are independent of the encoder.
OK, nice graphs, but how does it actually sound? The following samples demonstrate the effect of LACE or NoLACE on Opus wideband speech quality at different bitrates. We recommend listening with good headphones, especially for higher bitrates.
Select sample
Select enhancement
Select bitrate
Select where to start playing when selecting a new sample
Player will continue when changing sample.
Demonstrating the effect of LACE and NoLACE on speech quality at 6, 9, and 12 kb/s.
Using the deep PLC or the quality enhancements should typically require only minor code changes. DRED is an entirely different story. It requires closer integration with the jitter buffer to ensure that redundancy gets used.
In a real-time communications system, the size of the jitter buffer determines the maximum amount of packet arrival lateness that can be tolerated without producing an audible gap in audio playout. In the case of packet loss, we can treat the DRED data similarly to late arriving audio packets. We take care to only insert this data into the jitter buffer if we have observed prior loss. In ideal circumstances, an adaptive jitter buffer (like NetEq used in WebRTC) will try to minimize its size in order to preserve interactive latency. If data arrives too late for playback, there will be an audible gap, but the buffer will then grow to accommodate the new nominal lateness. If network conditions improve the buffer can shrink back down, using time scaling to play the audio at a slightly faster rate. In the case of DRED, there will always be a loss vs. latency tradeoff. In order to make use of the DRED data and cover prior lost packets, we will need to tolerate a larger jitter buffer. But because we treat DRED similarly to late packet arrival, we can take advantage of the existing adaptation in NetEq to provide a reasonable compromise in loss vs. latency.
You can try out DRED using the patches in our webrtc-opus-ng fork of the Google WebRTC repository. Using these patches, we were able to evaluate how DRED compares to other approaches. And yes, it still works well even with 90% loss. See the results below.
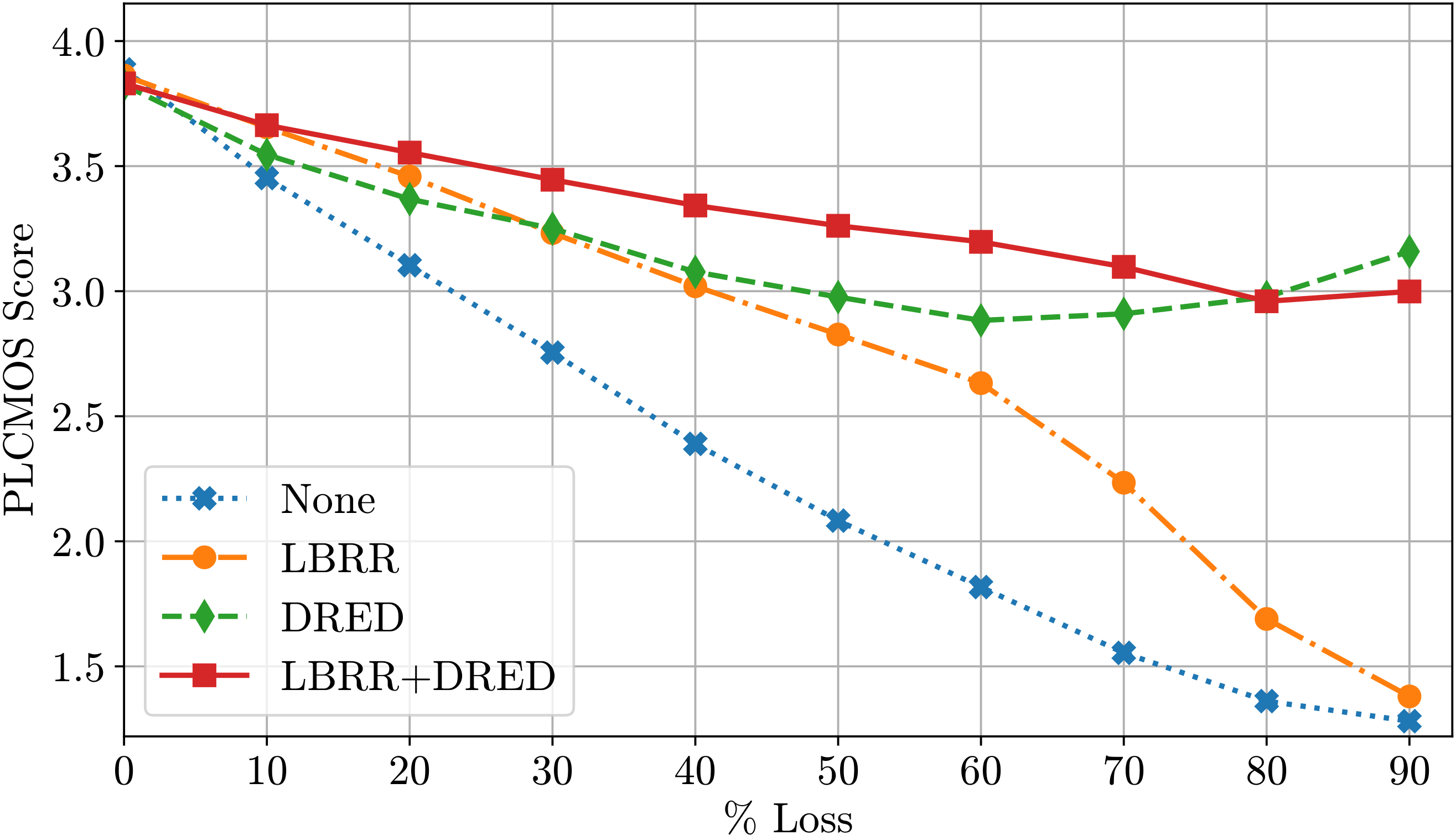
Of course, hearing is believing, so here are some samples produced with the WebRTC patches. These should be close to what one might experience during a meeting when packets start to drop. Notice some gaps at the beginning as the jitter buffer adapts and is then able to take full advantage of DRED.
Select loss rate
Select redundancy
Select where to start playing when selecting a new sample
Player will continue when changing sample.
Evaluating the effectiveness of the different redundancy options. These audio samples are generated using real packet loss traces with the entire WebRTC stack.
To ensure compatibility with the existing standard and future extensions of Opus, this work is being conducted within the newly-created IETF mlcodec working group. This effort is currently focused on three topics: a generic extension mechanism for Opus, deep redundancy, and speech coding enhancement.
The new DRED mechanism requires adding extra information to Opus packets while allowing an older decoder that does not know about DRED to still decode the regular Opus data. We found that the best way to achieve that was through the Opus padding mechanism. In the original specification, padding was added to make it possible to make a packet bigger if needed (e.g., to meet a constant bitrate even when the encoder produced fewer bits than the target). Thanks to padding, we can transmit extra information in a packet in a way that an older decoder will just not see (so it won't get confused). Of course, if we're going to all that trouble, we might as well make sure we're also able to handle any future extensions. Our Opus extension Internet-Draft defines a format within the Opus padding that can be used to transmit both deep redundancy, but also any future extension that may become useful. See our presentation at IETF 118 for diagrams of how the extensions fit within an Opus packet.
We are also working on standardizing DRED. Standardizing an ML algorithm is challenging because of the tradeoff between compatibility and extensibility. That's why our DRED Internet-Draft describes how to decode extension bits into acoustic features, but leaves implementers free to make both better encoders and also better vocoders that may further improve on the quality and/or complexity.
For enhancement, we also follow the general strategy to standardize as little as possible, since we also expect future research to produce better methods than we currently have. That's why we will specify requirements an enhancement method like LACE or NoLACE should satisfy in order to be allowed in an opus decoder rather than specifying the methods themselves. A corresponding enhancement Internet-Draft has already been created for that purpose.
Here are briefly some other changes in this release.
Opus now has support and run-time detection for AVX2. On machines that support AVX2/FMA (from around 2015 or newer), both the new DNN code and the SILK encoder will be significantly faster thanks to the use of 256-bit SIMD.
Existing ARMv7 Neon optimization were re-enabled for AArch64, resulting in more efficient encoding. The new DNN code can now take advantage of the Arm dot product extensions that significantly speed up 8-bit integer dot products on a Cortex-A75 or newer (~5 year old phones). Support is detected at run-time, so these optimizations are safe on all Arm CPUs.
As a side effect of trying to tune the DRED encoder to maximize quality, we realized we needed a better way of simulating packet loss. For some purposes, testing with random loss patterns (like tossing a coin repeatedly) can be good enough, but since DRED is specifically designed to handle burst loss (which is rare with independent random losses) we needed something better. As part of the Audio Deep Packet Loss Concealment Challenge, Microsoft made available some more realistic recorded packet loss traces. A drawback of such real data is that one cannot control the percentage of loss or generate sequences longer than those in the dataset. So we trained a generative packet loss model that can simulate realistic losses with a certain target overall percentage of loss. Packet loss traces are quite simple and our generative model fits in fewer than 10,000 parameters. To simulate loss with opus_demo, you need to build with --enable-lossgen. Then add -sim-loss <percentage> to the opus_demo command line. Note that the loss generator is just an initial design, so feedback is welcome.
Because we believe that this loss generator can be useful to other applications, we have made it easy to extract it from Opus and use it in other applications. The main source file for the generator is dnn/lossgen.c. Comments in the file contain information about the other dependencies needed for the loss generator.
We hope we demonstrated how our new ML-based tools substantially improve error robustness and speech quality with a very modest performance impact and without sacrificing compatibility. And we're only getting started. There's still more to come. We encourage everyone to try out these new features for themselves. Please let us know about your experience (good or bad) so we can continue to improve them. Enjoy!
—The Opus development team